Lambda 架构 是大数据量下的一种数据处理的架构,它同时使用批处理和流处理的方法处理大量数据。
Lambda 架构 是大数据量下的一种数据处理的架构,它同时使用批处理和流处理的方法处理大量数据。
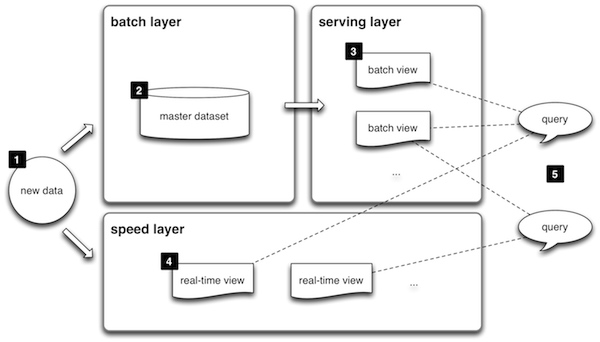
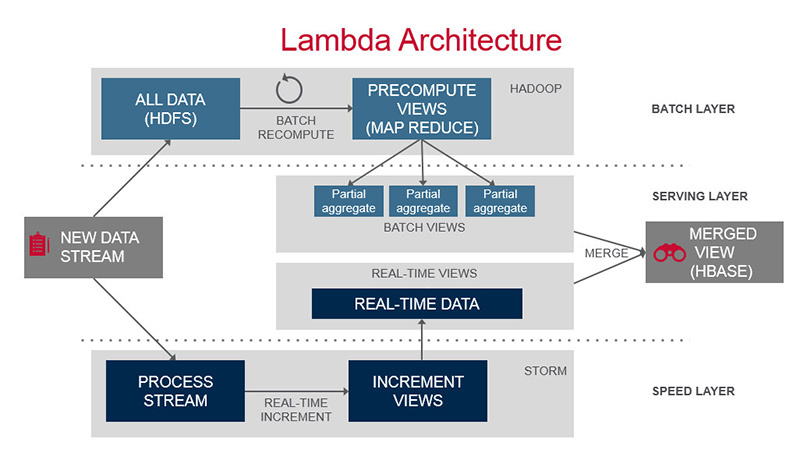
标准的 Lambda 架构包含 batch layer(批处理层)、serving layer(服务层)、speed layer(实时层)
批处理层:包含 master dataset(存储全量数据) 和 batch view (批处理视图)。batch view 是由 master dataset 计算得来
实时层:由于批处理层数据处理存在延时,如果想获得实时数据,需要实时层的支撑。speed layer 与 batch layer非常相似,它们之间最大的区别是 speed layer 只处理最近的数据,batch layer 则要处理所有的数据。改层一般使用实时计算引擎(如 Spark Streaming、Flink)完成计算
服务层:对最终结果的查询提供支撑,合并批处理层、实时层结果。 一般使用 NoSQL 数据库存储,如 HBase
Lambda 架构将两种异构的系统整合,实现了既能分又析历史数据,又能计算实时数据。历史数据保存了所有的明细,可以使用多变的方式分析;实时数据包含最新的信息,可以提供报警、及时分析等能力
由于实时层和批处理层使用的是不同架构的系统,因此需要对应开发不同的代码,而且需要对同样的数据处理两次:开发者需要熟悉不同的组件、需要维护数据的一致性,都是比较复杂的。Delta Lake 的出现,解决历史数据和实时数据需要不同系统处理的问题。
使用 Spark 将全量数据 (master dataset) 批处理为 批处理视图 (batch view),并保存在 NoSQL 数据库 Cassandra 中。使用 Akka 的调度器按一定的时间间隔调度执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class BatchProcessingUnit val sparkConf = new SparkConf ()"Lambda_Batch_Processor" ).setMaster("local[2]" )"spark.cassandra.connection.host" , "127.0.0.1" )"spark.cassandra.auth.username" , "cassandra" )val sc = new SparkContext (sparkConf)def start Unit ={val rdd = sc.cassandraTable("master_dataset" , "tweets" )val result = rdd.select("userid" ,"createdat" ,"friendscount" ).where("friendsCount > ?" , 500 )"batch_view" ,"friendcountview" ,SomeColumns ("userid" ,"createdat" ,"friendscount" ))
实时层使用 Spark Streaming 实时处理 Kafka 消息,同样将计算结果存储在 Cassandra 中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 object SparkStreamingKafkaConsumer extends App val brokers = "localhost:9092" val sparkConf = new SparkConf ().setAppName("KafkaDirectStreaming" ).setMaster("local[2]" )"spark.cassandra.connection.host" , "127.0.0.1" )"spark.cassandra.auth.username" , "cassandra" )val ssc = new StreamingContext (sparkConf, Seconds (10 ))"checkpointDir" )val topicsSet = Set ("tweets" )val kafkaParams = Map [String , String ]("metadata.broker.list" -> brokers, "group.id" -> "spark_streaming" )val messages: InputDStream [(String , String )] = KafkaUtils .createDirectStream[String , String , StringDecoder , StringDecoder ](ssc, kafkaParams, topicsSet)val tweets: DStream [String ] = messages.map { case (key, message) => message }ViewHandler .createAllView(ssc.sparkContext, tweets)
下面是 ViewHandler 的处理逻辑,主要是选择 follow 者数量大于 500 的记录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 object ViewHandler def createAllView SparkContext , tweets: DStream [String ]) = {def createViewForFriendCount SparkContext , tweets: DStream [String ]) = {RDD [String ], time: Time ) =>val spark = SparkSession .builder.config(rdd.sparkContext.getConf).getOrCreate()val tweets: DataFrame = spark.sqlContext.read.json(rdd)"tweets" )val wordCountsDataFrame: DataFrame = spark.sql("SELECT userId,createdAt, friendsCount from tweets Where friendsCount > 500 " )val res: DataFrame = wordCountsDataFrame.withColumnRenamed("userId" ,"userid" ).withColumnRenamed("createdAt" ,"createdat" ).withColumnRenamed("friendsCount" ,"friendscount" )SaveMode .Append )"org.apache.spark.sql.cassandra" )Map ( "table" -> "friendcountview" , "keyspace" -> "realtime_view" ))false )
服务层聚合了批处理层和实时层的数据,以满足 Ad hoc 的需要
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def findTwitterUsers Long , second: Long , tableName: String = "tweets" ): Response = {val batchInterval = System .currentTimeMillis() - minute * 60 * 1000 val realTimeInterval = System .currentTimeMillis() - second * 1000 val batchViewResult = cassandraConn.execute(s"select * from batch_view.friendcountview where createdat >= ${batchInterval} allow filtering;" ).all().toListval realTimeViewResult = cassandraConn.execute(s"select * from realtime_view.friendcountview where createdat >= ${realTimeInterval} allow filtering;" ).all().toListval twitterUsers: ListBuffer [TwitterUser ] = ListBuffer ()TwitterUser (row.getLong("userid" ), new Date (row.getLong("createdat" )), row.getLong("friendscount" ))TwitterUser (row.getLong("userid" ), new Date (row.getLong("createdat" )), row.getLong("friendscount" ))Response (twitterUsers.length, twitterUsers.toList)