这边文章由笔者在快手一个内部分享 《深入理解 ES 查询机制》 整理而来,主要介绍了 ElasticSearch在搜索时,如何快速定位到相关文档,并揭示了文档得分的细节。包括:
评分机制: ES 简介、TF/IDF 模型、空间向量模型、BM25 模型、模型在 ES 的实际体现;
索引机制: 倒排索引、如何快速定位 Term、Term Index FST(有限状态机索引)、Posting List:Frame Of Reference.
文末提供原始分享幻灯片下载链接。
ElasticSearch 简介
为什么需要使用 ES 进行搜索
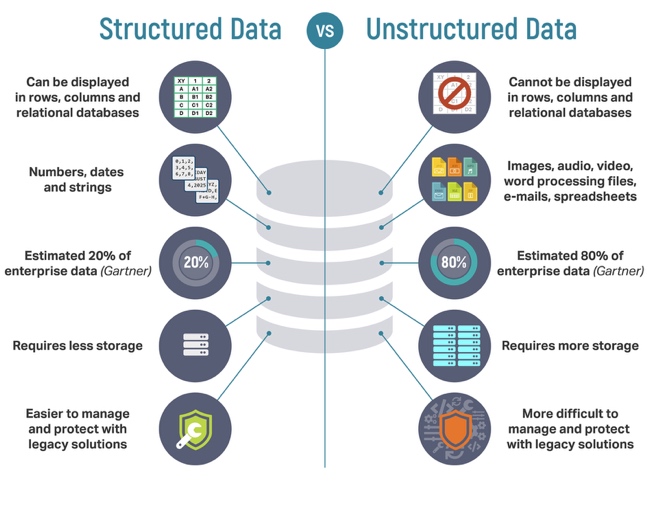
结构化数据 VS 非结构化数据
想了解为什么需要ES进行搜索,需要先对比一下结构化数据和非结构化数据。
- 结构化数据:
也称作行数据,关系型数据库进行存储和管理,是由二维表结构来逻辑表达和实现(可以使用行、列来表现)的数据,严格地遵循数据格式与长度规范。 - 非结构化数据:
又可称为全文数据,不定长或无固定格式,不适于由数据库二维表来表现,包括所有格式的办公文档、XML、HTML、word文档,邮件,各类报表、图片和音频、视频信息等。
其他的不同之处还有:
结构化数据往往占用的空间较小,占企业数据的 20% 左右,容易管理。
非结构化数据通常占用更多的存储空间,约占企业数据的 80% 左右,比较难以管理
结构化搜索 vs 全文搜索
结构化搜索:
通常查询具有固有结构的数据
答案要么是肯定的,要么是否定的(即便是类似正则匹配这样的结构化搜索,正则表达式匹配数据也是确定的)
数据要么属于查询结果集合,要么不属于。
全文搜索:
通常查询全文字段/文档的所有内容
答案返回的是一系列可能的数据
数据有一定概率属于结果集合
到这里,为什么需要使用 ES 进行搜索的答案就很明确了:对于非结构化文本(比如评论内容),传统的结构化搜索难以满足需求,于是就会使用 ES 进行全文搜索。当然 ES 不仅可以进行全文搜索,也可以进行一部分的结构化搜索,更加扩大了他的应用范围。对于数据量巨大的情景,有公司会使用 ES 代替传统的 MySQL 管理数据。
ES 基本概念介绍
本小结主要是介绍 ES 的一些基本概念,目的是方便之前没有了解过 ES 的同学可以理解这次分享所介绍的内容。
ES 存储模型
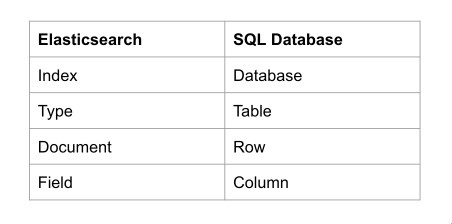
ES 在设计存储模型时,考虑了大家从关系型数据库转换肯能带来的困难,于是设计了 Index、Type、Document、Field 分别于对应传统关系型数据库(比如 MySQL) 的 Database、Table、Row、Column。
注意: ES 存储时,并没有 Type 的概念,同一个Index 里的 Type 会拍平存储,只是方便理解才会对使用者提供这样一个抽象。由于Type 的存在会带来一些问题,在后续的版本里会逐步移除,详情参见:https://www.elastic.co/guide/en/elasticsearch/reference/6.7/removal-of-types.html
ES 与 Lucene
ES 底层基于 Lucene 开发,Lucene作为其核心来实现索引和搜索的功能。我们虽然讲的是 ES,但很大一部分内容是 Lucene 的实现。
评分机制
ES 相似度(Similarity)机制
什么是相似度?
前文中讲到,全文搜索返回的数据是有一定概率属于结果集。相似度就是反应这个概率大小的指标。
ES 把每一篇文档与查询词的相似度计算出来,使用一个数值来表示(评分),然后按照评分又高到底的顺序返回前 n 条数据。这就是一次查询的大致过程。
如何计算相似度?
相似度是使用相关算法计算的,ES 内部(也就是 Lucene)使用的称为 Lucene实用评分函数,大致长这样:
下面会详细介绍每一部分的意义。
Lucene 评分函数的产生
Lucene 评分函数借鉴了词频/逆向文档频率(TF/IDF:term frequency/inverse document frequency)算法 和 向量空间模型(VSM:vector space model)
并于 ES 版本 5.0 将 TF/IDF 模型更换为 BM25 模型
下面分别介绍提到的这几个概念
词频/逆向文档频率(TF/IDF)
公式详解:
其中:
是词频得分,它的公式是:
tf 是要查询的词在一个文档中出现的次数。
是逆向文档频率的得分,等于文档频率 的倒数取log。
文档频率 就是要出现查询的词文档数与文档总数加一的比,代表了查询的词在全部文档中占的大小。
numDocs 即为文档总数; docFreq 即为出现要查询词出现在文档(这个概念对应关系型数据库的“记录”,见上文)中出现的次数;
IDF score 的意义在于考虑查询的词在文档总数出现的频率,对总分产生影响。查询的词在文档中出现的频率越高,对结果产生的影响越小。比如想 “的”,“你” 等常见的词几乎出现在每一个文档中,对结果会有很小的影响。
是字段长度归一值。它的计算方式为:
length 表示文档的长度。
fieldNorms 的意义在于考虑文档长度对于查询得分的影响。例如在一条短信中匹配到搜索的词与在一本书中匹配到,肯定是这个短信更有可能属于结果集。
将所有的分项带入,得到 TF/IDF 的公式:
TF/IDF 在 ES 中的体现
ES 中的数据:
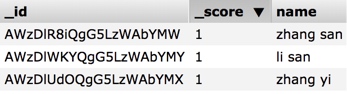
搜索”zhang“ 后,得到的前一条结果及其得分的详情:
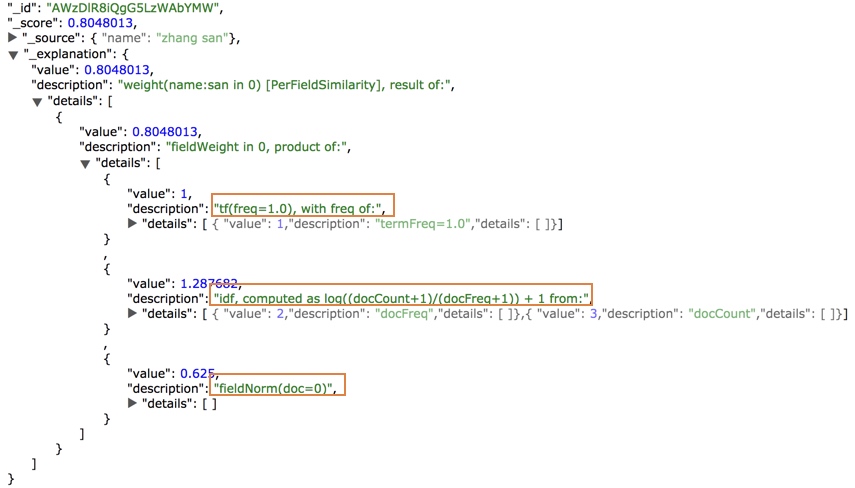
我们可以看到框选的部分: tf、idf、fieldNorm 分别对应前文公式的三个部分。感兴趣的同学可以自己具体计算一下得分。
空间向量模型 (VSM)
上面介绍的TF/IDF 模型是针对一个词来进行查询的,如果我们搜索多个词,改怎么处理呢?
向量空间模型(Vector Space Model) 提供一种比较多词查询的方式,模型将文档和查询都以 向量(vectors)的形式表示。
举例来说:[1]
假设我们有三个文档:
I am happy in summer 。
After Christmas I’m a hippopotamus 。
The happy hippopotamus helped Harry 。
我们要在这三个文档中搜索 “happy hippopotamus” (快乐的河马)
可以为每个文档都创建包括每个查询词 ( happy 和 hippopotamus )权重的向量(事实上使用的是得分,这里为了便于理解,人工指定了权重),然后将这些向量置入同一个坐标系中:
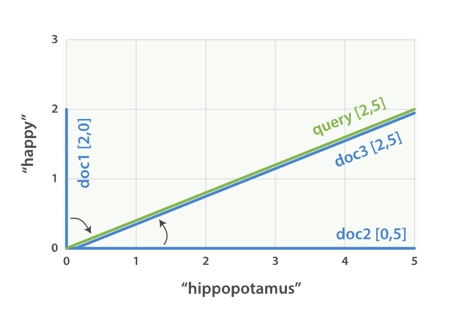
通过比较各个文档的向量与查询词的向量的夹角(计算时使用夹角的余弦值),来判断哪个文档与查询更为接近。
具体计算时,使用**余弦相似度**公式计算:
Lucene 实用评分函数
Lucene 实用评分函数是有余弦相似度公式演变而来。图中相同颜色的框代表的含义是一样的。
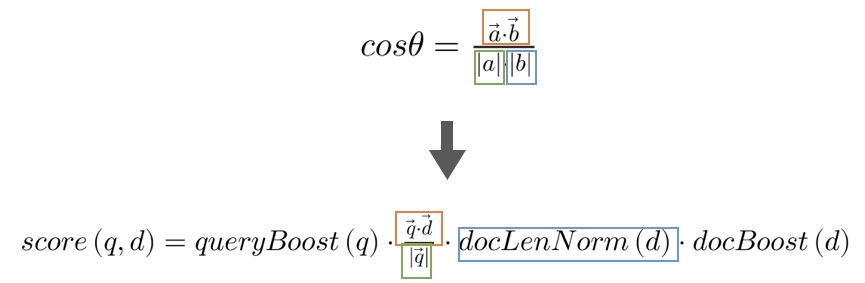
我们可以看到,Lucene 实用评分函数改变的是 增加了 和 。
上文提到过 ,考虑了文档的长度,而余弦相似度公式中对应的部分为 ,为 的单位长度,未考虑文档长度。
和 分别代表查询的权重提升和文档的权重提升,可以更为灵活的手工指定,影响搜索结果。
BM25 相似度
BM25 全称 Okapi BM25 是 Okapi Best Match 25 的缩写。
ES 版本 5.0 将 TF/IDF 模型更换为了 BM25 模型。BM25可以看做是 TF/IDF 的改良。
BM25 与 TF/IDF 相比,主要体现在 TF 和 fieldNorms 的计算上。
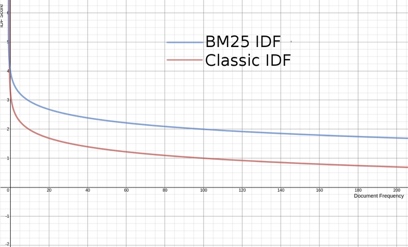
IDF
对于IDF,我们看到两者的趋势基本是一致的
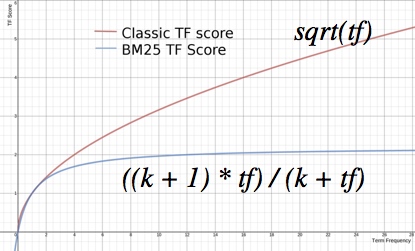
TF
对于 TF 我们看到,传统的 TF 曲线随着 tf(词频) 的升高,其值无限的增加,而 BM 25的
TF 值收敛到一个值()。在一定程度上,词频越高,固然得分也应该越高。但是不能没有限度。否则像是网页搜索,站长可以通过作弊,使得词频达到极高的值,就达到了垄断这个词的效果 了。
fieldNorms
BM25 将 fieldNorms 与词频进行合并,一起对得分产生影响,称为 tfNorm
tfNorm
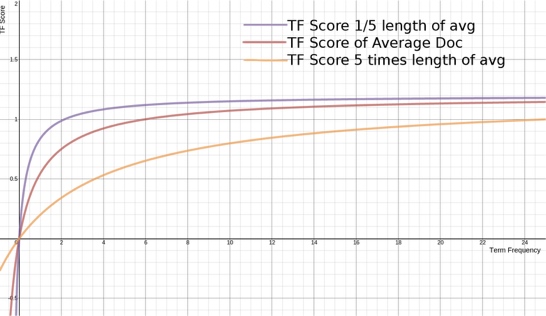
:表示文档的长度是平均文档长度的多少倍。计算方式:
参数的作用:调节 L 的影响程度,当b=0时,文档的长度对于结果没有影响
下图展示了文档长度对于得分的影响:
BM25 公式
将以上部分组合起来,我们得到了 BM25 的公式:
更多
分享的第二部分,请查看 深入理解 ES 查询机制[二](即将推出)
扩展阅读
来自 ElasticSearch 权威指南:https://www.elastic.co/guide/cn/elasticsearch/guide/current/scoring-theory.html ↩︎